High throughput event ingest
Metronome’s infrastructure supports up to 110,000 events per second (6.6 million events per minute) without requiring pre-aggregation or rollups. Default ingest rate limit starts at 5,000 events per second. If you need higher throughput, contact Metronome to increase it. When scaling to send high event volumes, batching your events helps you take full advantage of this capacity. You can batch 100 events per request sent to Metronome’s ingest endpoint. To do so, submit an array of usage event objects using a POST request and sending events whose schema matches the structure outlined. Learn more about sending usage to Metronome here.Monitor event data in the UI
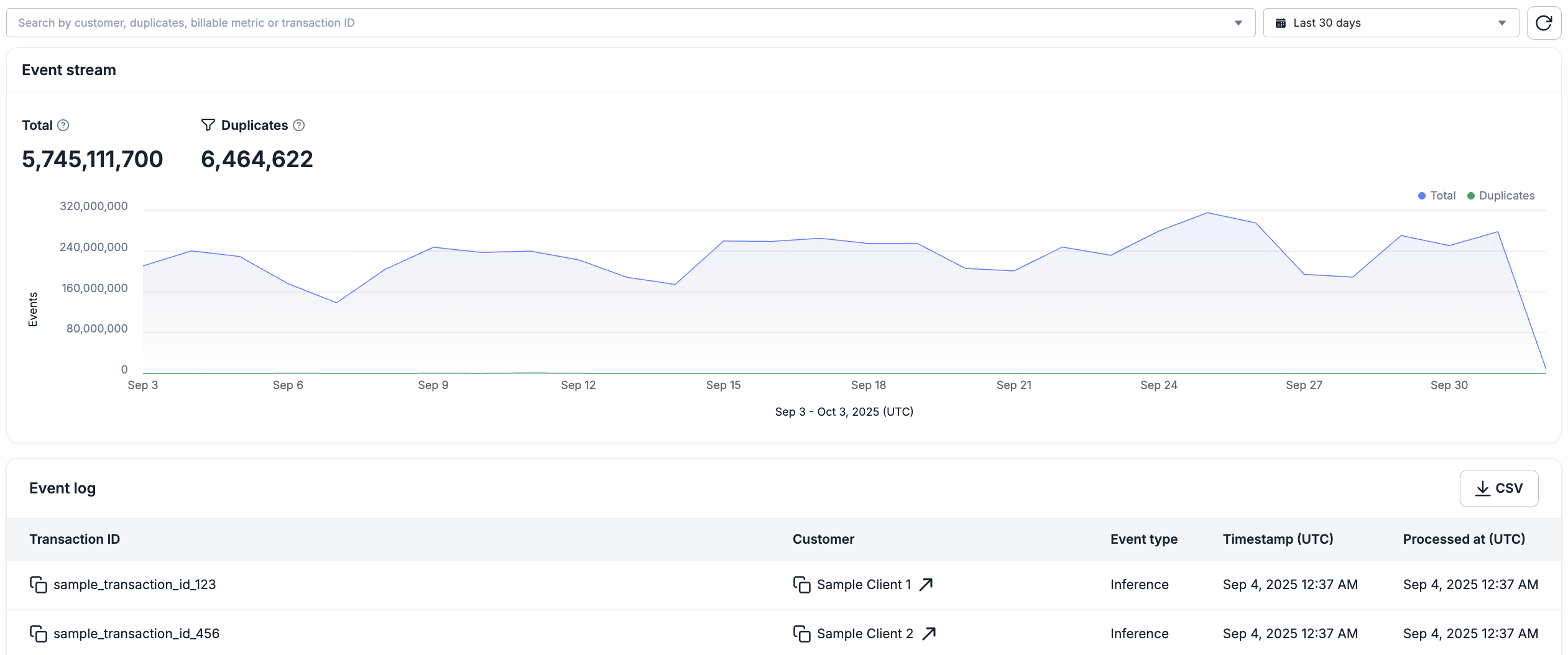
The Metronome UI offers direct access to inspect your event pipeline through our dedicated event explorer. This feature is useful to validate that Metronome has successfully ingested events, that they’ve been successfully matched to Metronome objects like Billable Metrics, and to identify duplicate events. With the events UI, you can:- See summary-level time-based entire event stream or isolated duplicate event graphs
- Includes custom time-frame viewing options
- Search by customer, duplicates, billable metrics, and transaction IDs
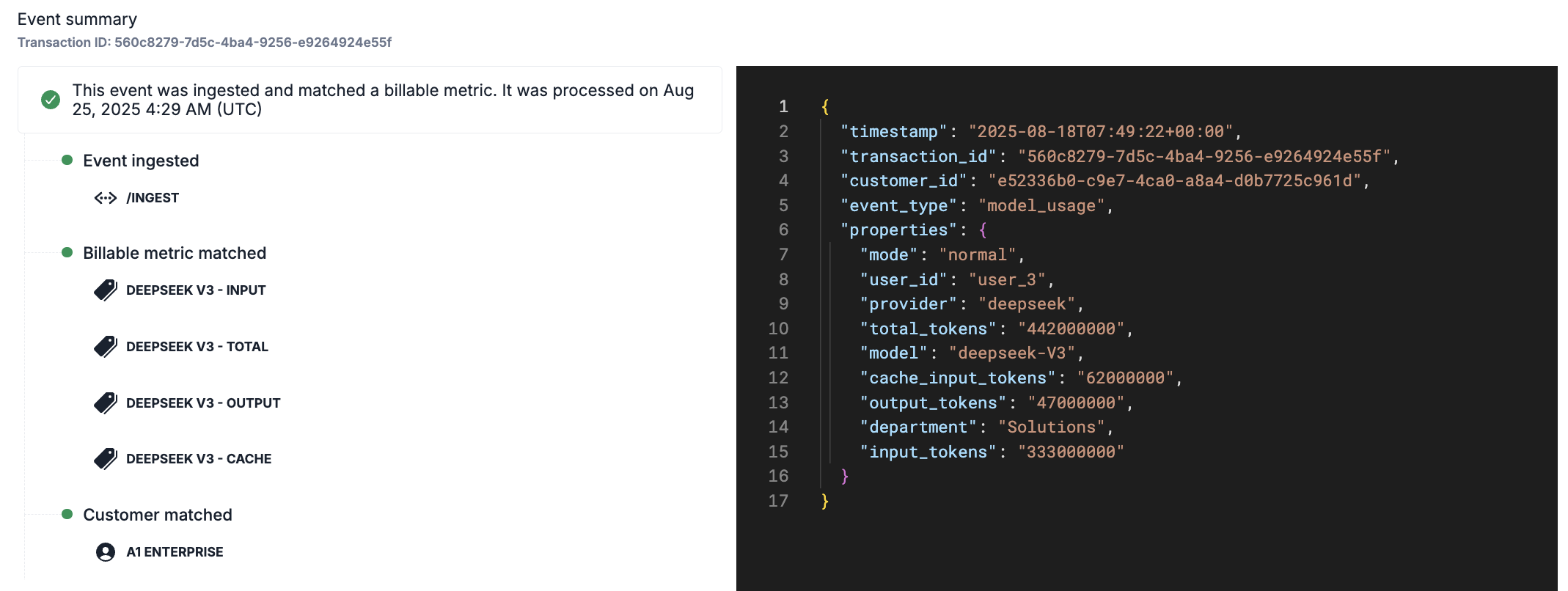
- View complete usage event payloads from individual events
- View usage event attribution to matched customer and billable metrics
- Export a CSV event log
Maintaining data integrity at scale
The Metronome UI is great for spot-checking and quick validation. For sustained reliability at high volumes, you’ll want automated, programmatic checks that run continuously and alert you before issues affect customers or revenue. Use the guidance below to build a more scalable event posture. High-volume event ingestion requires effective monitoring and maintenance of your event pipeline. Metronome provides end-to-end visibility and self-serve tooling to help you resolve issues before they impact your business.- Queue and Retry: You should follow industry-standard best practices around queueing, retries, message queue logging, alerting, and use of dead-letter queues. Please see here for Metronome’s recommendations.
- Usage Pipeline Observability: Metronome’s Event Search API allows you to sample raw events and validate that they are matching active billable metrics. This is a critical control for preventing silent revenue loss if an upstream system changes an event schema.
- Seamless Backfills and Recovery: If an incident occurs, you need to be able to recover data quickly. Metronome offers a 34-day historical ingest and deduplication window processed through the same ingest endpoint. This extended window ensures you can replay more than 24 hours of traffic and re-rate draft invoices and credit ledgers in real time. Corrections beyond 34 days is handled by our operations team and is usually completed promptly.